

LongReward是清华大学、中国科学院、智谱AI联合推出的,基于AI反馈改进长文本大型语言模型(LLMs)性能的方法。LongReward从有用性、逻辑性、忠实性和完整性四个维度为模型响应打分,提供奖励信号,强化学习的方式优化模型,让模型在处理长文本时更准确、一致,能更好地遵循指令。提升模型的长文本处理能力,增强遵循简短指令的效率。

(图片来源网络,侵删)

(图片来源网络,侵删)
LongReward是清华大学、中国科学院、智谱AI联合推出的,基于AI反馈改进长文本大型语言模型(LLMs)性能的方法。LongReward从有用性、逻辑性、忠实性和完整性四个维度为模型响应打分,提供奖励信号,强化学习的方式优化模型,让模型在处理长文本时更准确、一致,能更好地遵循指令。提升模型的长文本处理能力,增强遵循简短指令的效率。

Make-A-Character(简称Mach)是一个由阿里巴巴集团智能计算研究院开发的一个人工智能3D数字人生成框架,旨在通过文本描述快速创建逼真的3D角色。该系统特别适用于满足人工智能代理和元宇宙中对个性化和富有表现力的...
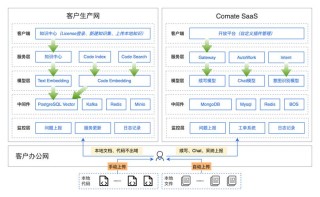
Mahilo 是灵活的多智能体框架,支持创建与人类互动的多智能体系统。Mahilo支持实时语音和文本通信,智能体之间能自主共享上下文和信息,保持人类对交互的监督和控制。Mahilo 提供强大的组织级策略管理功能,确保所有智能...
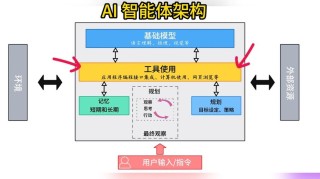
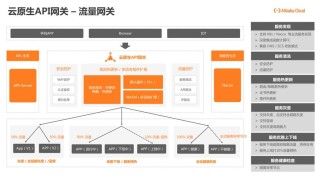
Magnitude 是开源的视觉 AI Agents驱动的端到端测试框架。Magnitude基于自然语言构建测试用例,用强大的推理代理规划和调整测试流程,基于快速的视觉代理执行测试。Magnitude 支持本地运行和 CI/...
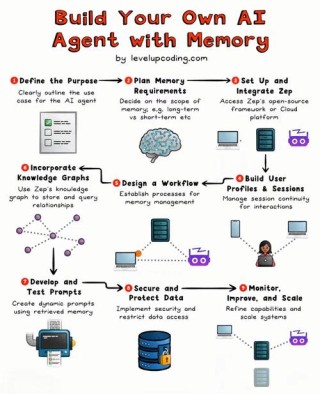
Magma 是微软研究院推出的新型多模态AI基础模型,能为多模态人工智能代理(AI agents)提供通用能力。Magma能理解和执行多模态输入的任务,覆盖数字和物理环境。Magma基于大规模的视觉-语言数据和动作数据进行预...

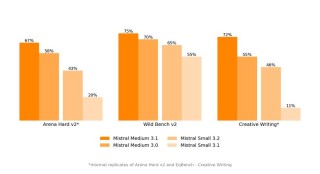
Magistral 是 Mistral AI 推出的推理模型,核心聚焦在透明、多语言和特定领域的推理能力。模型包含 Magistral Small(开源版)和 Magistral Medium(企业版), Magistral...

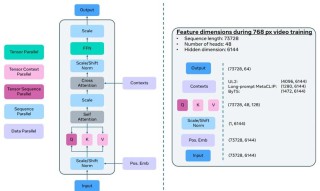
MagicTryOn是浙江大学计算机科学与技术学院、vivo移动通信等机构推出的基于视频扩散Transformer的视频虚拟试穿框架。框架替换传统的U-Net架构为更具表现力的扩散Transformer(DiT),结合全自注...


MagicTailor 是专门为组件可控个性化设计的新框架,让T2I模型在个性化过程中能够精确控制。MagicTailor 基于两个关键技术动态掩码退化(DM-Deg)和双流平衡(DS-Bal),解决语义污染和语义不平衡的挑...
MagicQuill是香港科技大学、蚂蚁集团、浙江大学和香港大学共同推出的开源AI互动式图像编辑工具。基于用户友好的界面和AI支持的智能建议,实现精确的局部图像编辑。用户用简单的笔触和提示词,轻松添加元素、擦除物体或改变颜色...


全部评论
留言在赶来的路上...
发表评论