

MUMU是一种多模态图像生成模型,通过结合文本提示和参考图像来生成目标图像,从而提高生成的准确率和质量。MUMU模型的架构基于SDXL的预训练卷积UNet,采用了视觉语言模型Idefics2的隐藏状态构建。模型在训练时使用了合成数据和真实数据,通过分两个阶段的训练过程,MUMU能更好地保留条件图像的细节,并在风格转换和角色一致性等任务上展现出泛化能力。

(图片来源网络,侵删)

(图片来源网络,侵删)
MUMU是一种多模态图像生成模型,通过结合文本提示和参考图像来生成目标图像,从而提高生成的准确率和质量。MUMU模型的架构基于SDXL的预训练卷积UNet,采用了视觉语言模型Idefics2的隐藏状态构建。模型在训练时使用了合成数据和真实数据,通过分两个阶段的训练过程,MUMU能更好地保留条件图像的细节,并在风格转换和角色一致性等任务上展现出泛化能力。

MeteoRA 是南京大学计算机科学与技术系的研究团队推出的用于大型语言模型(LLM)的多任务嵌入框架,将多个任务特定的 LoRA(低秩适配器)集成到一个基础模型中,实现高效的参数复用和自主任务切换。...
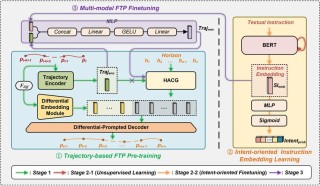
MetaStone-S1是原石科技推出的反思型生成式大模型,首次融合深度推理与推理链自筛选能力。模型核心用自监督反思范式,基于共享主干的策略模型和过程评分模型(SPRM),仅增加53M参数即可实时评估推理步骤质量,无需人工标...

MetaStone-L1-7B 是 MetaStone 系列中的轻量级推理模型,专为提升复杂下游任务的性能而设计。在数学和代码等核心推理基准测试中达到了并行模型的顶尖水平(SOTA),与 Claude-3.5-Sonnet-...

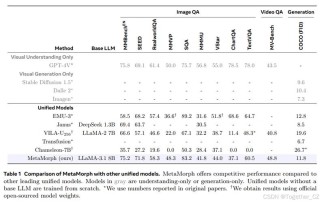
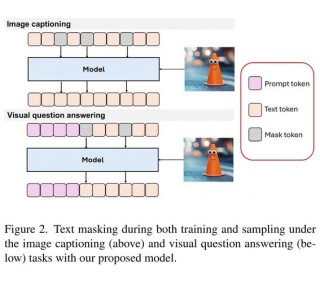
MetaMorph是多模态大模型(MLLM),通过指令微调(Instruction Tuning)实现视觉理解和生成。它提出了一种名为Visual-Predictive Instruction Tuning(VPiT)的方法...
MetaHuman-Stream 是一项前沿的实时交互流式AI数字人技术,集成了 ERNerf、MuseTalk、Wav2lip 等多种先进模型,支持声音克隆和深度学习算法,确保对话流畅自然。通过全身视频整合和低延迟通信技术...

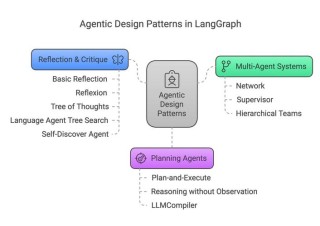
MetaGPT是一个创新的元编程框架,结合了大语言模型和多智能体协作系统,旨在通过模拟人类工作流程来解决复杂问题。该框架的核心在于将标准化操作程序(SOPs)编码成提示序列,以便在多智能体系统中实现更高效的工作流程和减少错误...
Meta Motivo 是 Meta 公司推出的AI模型,能提升元宇宙体验的真实性。Meta Motivo基于控制虚拟人形智能体的全身动作,模拟人类行为,增强用户互动。模型采用无监督强化学习算法,特别是FB-CPR算法,用大...
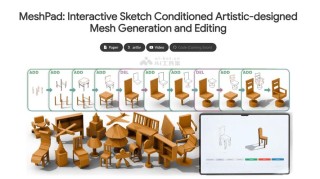
MeshPad 是基于草图输入的交互式艺术化网格生成与编辑工具,能将简单的二维草图迅速转化为高质量的 3D 网格模型,支持实时编辑。用户在草图上添加或删除线条,可对 3D 网格进行修改,如删除区域或添加新几何形状。...
全部评论
留言在赶来的路上...
发表评论