

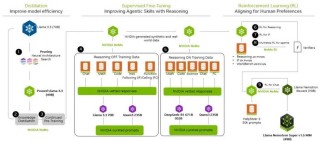
Moshi是由法国的的人工智能研究实验室Kyutai推出的一款端到端实时音频多模态AI模型,拥有听、说、看的能力,并能模拟70种不同的情绪和风格进行交流。作为平替的开源模型,Moshi在普通笔记本上即可运行,具有低延迟特性,支持本地设备使用,保护用户隐私。Moshi的开发和训练流程简单高效,由8人团队在6个月内完成,将很快开源模型的代码、权重和技术论文,免费供全球用户使用和进一步研究开发。
目前,Moshi主要支持英语和法语,暂不支持中文普通话。此外,Kyutai团队表示后续很快将开源Moshi,公布代码、模型权重和论文。

(图片来源网络,侵删)

(图片来源网络,侵删)





全部评论
留言在赶来的路上...
发表评论