

NanoFlow 是一个高性能的服务框架,专为大型语言模型(LLMs)设计,以提高模型的推理吞吐量。它通过在单个设备内部并行使用计算、内存和网络资源,优化了模型的推理过程。并行处理机制使得 NanoFlow 能同时处理更多的请求,并且保证快速响应,从而显著提升了系统的整体性能和用户体验。

(图片来源网络,侵删)
NanoFlow 是一个高性能的服务框架,专为大型语言模型(LLMs)设计,以提高模型的推理吞吐量。它通过在单个设备内部并行使用计算、内存和网络资源,优化了模型的推理过程。并行处理机制使得 NanoFlow 能同时处理更多的请求,并且保证快速响应,从而显著提升了系统的整体性能和用户体验。

OmniFlow是松下与加州大学洛杉矶分校(UCLA)合作推出的多模态AI模型。模型能实现文本、图像和音频之间的任意到任意(Any-to-Any)生成任务,例如将文本转换为图像或音频,或将音频转换为图像等。OmniFlow扩...
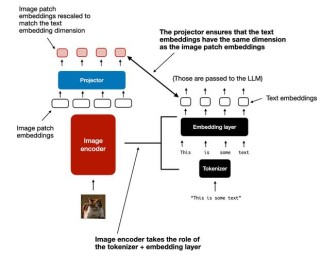

OmniEdit是先进的图像编辑技术,通过结合多个专家模型的监督来训练一个通用模型,处理多种图像编辑任务。能处理不同纵横比的图像,七种不同的图像编辑任务,包括对象替换、移除、添加等,支持任意宽高比和分辨率。...
OmniCorpus是一个大规模多模态数据集,包含86亿张图像和16960亿个文本标记,支持中英双语。由上海人工智能实验室联合多所知名高校及研究机构共同构建。OmniCorpus通过整合来自网站和视频平台的文本和视觉内容,提...

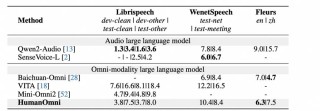
OmniConsistency 是新加坡国立大学推出的图像风格迁移模型,能解决复杂场景下风格化图像的一致性问题。模型基于大规模配对的风格化数据进行训练,用两阶段训练策略,将风格学习与一致性学习解耦,在多种风格下保持图像的语义...

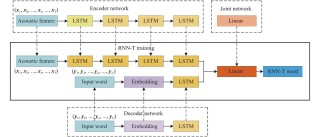
OmniCam 是先进的多模态视频生成框架,通过摄像机控制实现高质量的视频生成。支持多种输入模态组合,用户可以提供文本描述、视频中的轨迹或图像作为参考,精确控制摄像机的运动轨迹。...
OmniBooth是华为诺亚方舟实验室和港科大研究团队共同推出的图像生成框架,支持基于文本提示或图像参考进行空间控制和实例级定制。框架用用户定义的掩码和相关联的文本或图像指导精确控制图像中对象的位置和属性,提升文本到图像合成...


OmniAvatar是浙江大学和阿里巴巴集团共同推出的音频驱动全身视频生成模型。模型根据输入的音频和文本提示,生成自然、逼真的全身动画视频,人物动作与音频完美同步,表情丰富。...
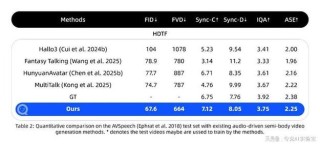
OmniAudio-2.6B是Nexa AI推出的音频语言模型,专为边缘部署设计,能实现快速且高效的音频文本处理。OmniAudio-2.6B是具有2.6亿参数的多模态模型融合Gemma-2-2b、Whisper Turbo...
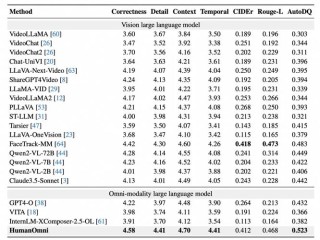
全部评论
留言在赶来的路上...
发表评论