

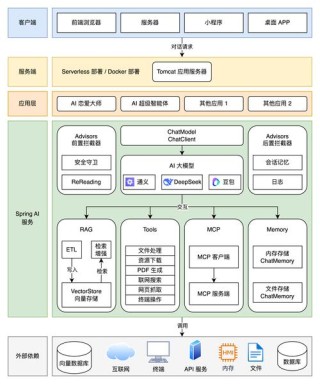
OSUM(Open Speech Understanding Model)是西北工业大学计算机学院音频、语音与语言处理研究组推出的开源语音理解模型。OSUM结合Whisper编码器和Qwen2 LLM,支持(ASR)、语音情感识别(SER)、说话者性别分类(SGC)等多种语音任务。OSUM基于“ASR+X”多任务训练策略,用模态对齐和目标任务的优化,实现高效稳定的训练。OSUM用约5万小时的多样化语音数据进行训练,性能在多项任务中表现优异,在中文ASR和多任务泛化能力上表现出色。

(图片来源网络,侵删)

(图片来源网络,侵删)








全部评论
留言在赶来的路上...
发表评论