

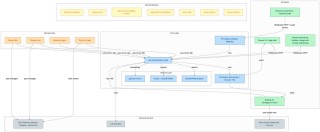
OThink-MR1是OPPO研究院和香港科技大学(广州)联合推出的多模态语言模型优化框架。基于动态调整Kullback-Leibler(KL)散度策略(GRPO-D)和奖励模型,提升多模态模型在复杂任务中的泛化推理能力。OThink-MR1在视觉计数和几何推理等多模态任务中表现出色,在同任务验证中超越传统的监督微调(SFT)方法,在跨任务泛化实验中展现强大的适应性。OThink-MR1为多模态模型的通用推理能力发展开辟新路径,有望在更多领域发挥重要作用。

(图片来源网络,侵删)

(图片来源网络,侵删)








全部评论
留言在赶来的路上...
发表评论