

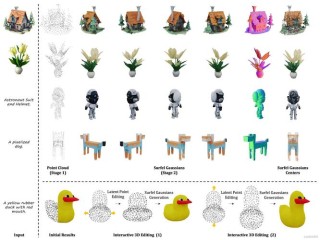
Qwen VLo 是通义千问团队推出的多模态统一理解与生成模型。在多模态大模型的基础上进行了全面升级,能“看懂”世界,能基于理解进行高质量的再创造,实现了从感知到生成的跨越。能精准理解图像内容,在此基础上进行一致性和高质量的生成。用户可以通过自然语言指令要求模型对图像进行风格转换、场景重构或细节修饰,模型能灵活响应并生成符合预期的结果。Qwen VLo 支持多语言指令,打破语言壁垒,为全球用户提供便捷的交互体验。具备动态分辨率训练与生成的能力,支持任意分辨率和长宽比的图像生成,适用于多种场景。

(图片来源网络,侵删)

(图片来源网络,侵删)






全部评论
留言在赶来的路上...
发表评论