

Liquid是华中科技大学、字节跳动和香港大学联合推出的极简统一多模态生成框架。基于VQGAN将图像编码为离散的视觉token,与文本token共享同一词汇空间,让大型语言模型(LLM)无需修改结构实现视觉生成与理解。Liquid摒弃传统外部视觉模块,用LLM的语义理解能力进行多模态任务,显著降低训练成本(相比从头训练节省100倍),在视觉生成和理解任务中表现出色,超越部分扩散模型。Liquid揭示了多模态任务的尺度规律,证明随着模型规模增大,视觉与语言任务的冲突逐渐消失,且两者能相互促进。

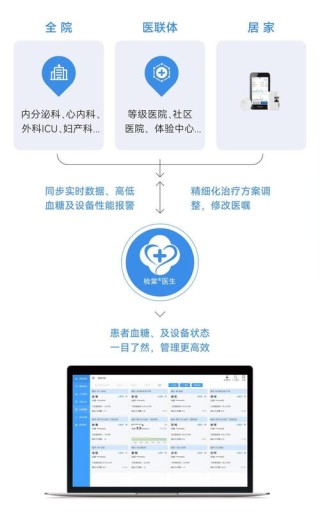
(图片来源网络,侵删)

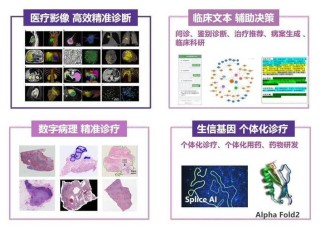
(图片来源网络,侵删)





全部评论
留言在赶来的路上...
发表评论