

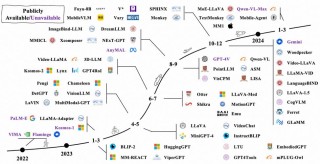
NEXUS-O 是HiThink 研究院、英国帝国理工学院、浙江大学、复旦大学、微软、Meta AI等机构推出的多模态AI模型,能实现对语言、音频和视觉信息的全方位感知与交互。NEXUS-O能处理音频、图像、视频和文本的任意组合输入,用音频或文本形式输出结果。NEXUS-O 基于视觉语言模型预训练,用高质量合成音频数据提升三模态对齐能力。NEXUS-O引入新的音频测试平台 Nexus-O-audio,涵盖多种真实场景(如会议、直播等),用在评估模型在实际应用中的鲁棒性。NEXUS-O 在视觉理解、音频问答、语音识别和语音翻译等任务上表现出色,基于三模态对齐分析展示了高效性和有效性。

(图片来源网络,侵删)

(图片来源网络,侵删)






全部评论
留言在赶来的路上...
发表评论